第7章虛擬記憶體(virtual memory)
1. 分段式的虛擬記憶體機制
2. 分頁的虛擬記憶體機制
3. 分段分頁的虛擬記憶體配置技術的比較。
早期的程式設計者要想辦法讓程式寫得不占有那麼多空間,後來有人想到可以把程式分段,這些段落也稱為overlay,需要用到的段落就搬到主記憶體,雖然系統可以做到overlay在磁碟與主記憶體之間的搬移,但是對於程式設計者來說,程式的分段實在煞費苦心。倒是overlay的觀念引發了後來虛擬記憶體的觀念,解決了之前的問題。
虛擬記憶體的技術可以分成分頁法(paging)與分段法(segmentation)兩大類,虛擬記憶體要靠記憶體管理程式(memory manager)與處理器的合作,記憶體管理程式追蹤分頁(page)與分段(segment)的使用,處理器則需要在適當的時機產生中斷(interrupt),處理虛擬位址。

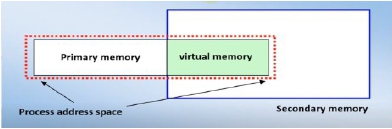
虛擬記憶體的機制可以讓沒有完全存在於主記憶體中的處理元能夠執行,換句話說,處理元的位址空間(address space)並沒有完全載入到主記憶體中。做法是把處理元的位址空間分割,如此一來,需要用到的位址空間分割
以程式碼區段(code segment)來說,不同的執行階段往往用到的分割不同,這裡的分割是指主記憶體上的一部分儲存空間,例如多數程式在剛開始的時候多半會對一些資料結構做啟始化的處理,並且輸入資料,然後會進入密集的運算階段,最後則會輸出結果。
資料區段(data segment)也有類似的特徵,我們把這種特性稱為空間引用的區域化特性(spatial reference locality)。當處理元在進行某一階段的執行時,它的spatial locality可定義為所引用位址的集合,因為這一階段的引用會集中在這個集合中的位址。當處理元進入另一個階段的執行時,locality也會跟著改變。
降低系統整體的記憶體空間的需求:
1. 記憶體管理員必須能接受位址空間的分割。
2. 位址空間的分割必須能載入並且動態地連結到程式所用的位址。
虛擬記憶體管理員在secondary memory建立的虛擬位址空間(virtual address space)可以看成是實體記憶體的抽象化,當系統運作時,虛擬記憶體管理員會自動控制主記憶體與虛擬記憶體之間的對應,促成資料方塊在主記憶體與次記憶體間自動的移轉。要完全了解實際的機制與細節,必須進一步地認識memory map table與page map table的內涵與使用方式。
當程式編譯時,其實已經開始有虛擬位址空間與程式位址空間之間的對應關係,不過得等到執行時期,虛擬位址才會連結(bind)到實體的記憶體位址。簡單地說,虛擬記憶體技術可以讓處理元引用(reference)很大的位址空間,但實際執行時卻只需要較少量的實體記憶體空間,當引用的資料不在實體記憶體中,則需要運用軟體的技術將資料找到並且載入。
對於交換系統(swapping system)來說,並不需要區分絕對模組(absolute module)與主記憶體中的位址空間,因為兩者大小相同,差異只在於重定位的值(relocation value)。但對於虛擬記憶體來說,符號名稱(symbolic name)、虛擬位址(virtual address)和實體位址空間(physical address space)是有差異的,3者之間有對應的關係(mappings)。虛擬位址與實體位址之間的對應有兩種方式:
1. 分段法(segmentation)。
2. 分頁法(paging)。
原始程式中有符號名稱(symbolic identifier)、標籤(label)與變數(variable)等形成所謂的名稱空間(name space)。當程式轉譯成絕對映像(absolute image)時,這些名稱會對應到虛擬位址,當程式的絕對映像轉換成可執行的映像(executable image)時,虛擬位址會再對應到主記憶體中的實體位址(physical address)。
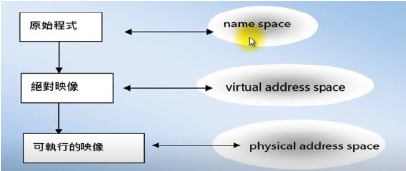
虛擬記憶體管理員要支援所謂的動態載入(dynamic loading)的功能,在執行時期把虛擬位址與實體位址連結(bind)起來。這種對應會隨時間而改變,所以是一種動態的對應關係。在真正運作的過程中,程式引用的物件不在記憶體內時,處理元的執行會暫停,虛擬記憶體管理員要載入引用的物件,同時重建所謂的位址轉換對應關係(address translation map)
記憶體空間的管理策略最常見的有「分頁(paging)」與「分段(segmenting)」兩大類,不管採用哪一種方式,執行程式的大小不能超過實體記憶體空間的大小,因為要將程式整個放到實體記憶體中才能執行。虛擬記憶體要打破這樣的限制,容許「執行程式的大小超過實體記憶體空間的大小」,解決的辦法是讓程式的某些還不會用到的部分先放在儲存媒體上,需要的時候才載入到實體記憶體中。
對於使用者的程式來說,可以引用的記憶體空間是虛擬記憶體空間,大於實體記憶體空間,所以對於所有正在執行狀態的處理元來說,有的處理元對應的執行程式可能沒有完全在實體記憶體中,而是儲存在儲存媒體上.

顯示確認分頁是否在實體記憶體中的方式,從記憶體空間的對應表格可以發現虛擬記憶體分頁1、4 與5目前的檢查位元為「v」,表示這些分頁目前有存在於實體記憶體中,虛擬記憶體分頁1是p1,儲存在實體記憶體中的分頁3。透過這種方式就可以檢查出特定的內容是否需要從儲存媒體取得,還是可以直接從實體記憶體中存取。
分段式的虛擬記憶體機制(segmentation)和前面提到的relocation register與limit register的方法近似,由程式設計者本身決定程式的分割方式,產生大小不一的分段(segment),例如UNIX C compiler訂的text, data與stack segment。分割之後,記憶體空間的位置就可以用:<分段號碼, 平移量(offset)>來決定。分段號碼指定記憶體的某個區塊,平移量指所在之處與分段起點之間的距離。分段本身就成為虛擬記憶體管理員在主記憶體與次記憶體之間移動資料的單位。
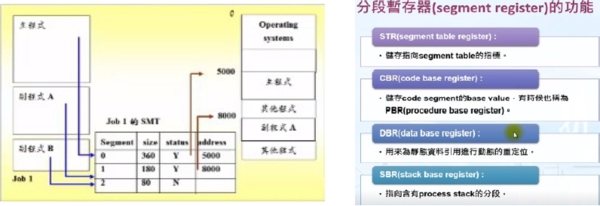
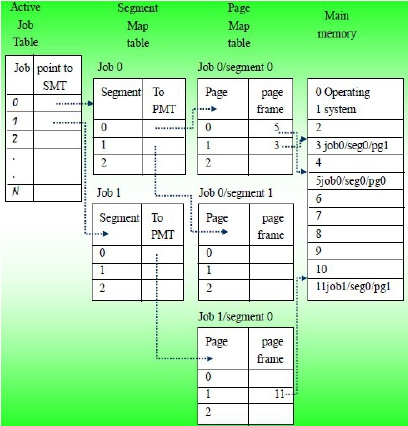
分段的由來是程式的結構化,也就是把程式分成模組(modules),所以在分段式的記憶體配置法中,我們把job分成大小不一的幾個分段(segment),每個分段剛好對應到一個模組,通常模組內執行的是相關的功能,副程式(subroutine)就可以看成是一種模組。在分段法中主記憶體不必再分割成page frames,當程式編譯與處理的過程中,系統會開始建立分段的資訊,每個job會有一個分段對應表格(SMT, segment map table),裡面記載分段的號碼、分段的長度、存取的權限、狀態與在記憶體中的位置。
記憶體管理員必須記錄記憶體中的分段,結合動態分割與demand paging的記憶體管理技術。Job table列出處理中的jobs,整個系統只有一個job table,SMT(segment map table)列出每個分段的細節,每個job有一個SMT,MMT(memory map table)記錄主記憶體的分配,整個系統只有一個MMT。

segment 1載入以後從8000的位置開始,job 1的SMT有這樣的記錄,所以系統可以找到segment 1。假如某個指令要求從副程式A的第100行開始執行,則系統要把第100行距離副程式A開端的距離再加上8000才能得到在主記憶體中的實際位址。

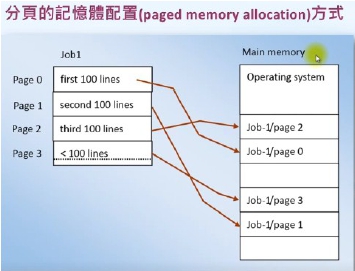
分頁的記憶體配置(paged memory allocation)方式將CPU所要處理的job分成大小一樣的分頁(page),有的作業系統以記憶體區塊的大小為分頁的大小,而且也剛好跟磁碟上區塊的大小一樣,假如要以名詞來稱呼這些不同的儲存單位,可以用下面的名稱:
1. 磁碟上的區塊: 稱為sector或block。
2. 主記憶體的區塊: 稱為page frame。
3. job的區塊: 稱為page。
分頁的虛擬記憶體機制(paging)使用單一成份的位址,虛擬記憶體空間分成線性的(linear)虛擬位址,程式設計者不需要知道虛擬記憶體空間如何運作,完全由虛擬記憶體管理程式負責把固定大小的分頁(page)依照需求在主記憶體與次記憶體之間移動。在實作上,分頁機制比較簡單,使用者對於技術上的細節不必了解。每個處理元的虛擬位址空間分成邏輯上的分頁,外部空間散佈的問題(external fragmentation)比較小。
各種靜態記憶體配置的演算法的主要差異是在取用政策與替換政策。假設N是virtual address space中的分頁的集合,則分頁引用的串列(page reference stream)可以表示如下:
w = r1, r2, r3, ……, ri, ……
w代表程式執行過程中引用到的分頁,這些分頁被引用的順序對於系統效能的影響很大,不過以實際的情況來看,很難在程式執行以前精確地預測出分頁引用的順序。
取用政策(fetch policy) : 在程式執行過程中的任意時間t,出現在引用順序中的分頁為Pt時,下面所列的是可能出現的幾種狀況:
1. 假如Pt在(t-1)時已經載入,則不需要進行任何處理。
2. 假如Pt在(t-1)時還未載入,而且分配給程式的page frame還有空的,則將[引用的分頁載入到空的page frame中。
3. 假如Pt在(t-1)時還未載入,而且分配給程式的page frame沒有空的,則必須進行置換。
依需求分頁(demand paging)的觀念是指只將程式的一部分載入到記憶體中,原本在job開始執行一直到結束,整個job都要放在記憶體中,假如程式引用到沒有載入的分頁,再將分頁載入到page frame。前面已經介紹過fetch policy與placement policy,在靜態記憶體配置的演算法中,這兩者都比較固定,所以下面的介紹以replacement policy為主。
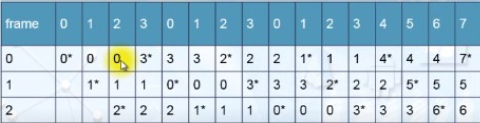
在隨機的替換(random replacement)政策中,被替換的分頁是隨機挑選的,所以完全沒有考慮到資料使用的特性。一般說來,這種方法的效能不佳,會造成很多page faults。Belady的演算法是一種理想中的演算法,也稱為Belady’s optimal algorithm,在挑選替換的分頁時,會選最久會再被用到的分頁來替換。假設主記憶體有3個page frame分配給目前的job,而分頁使用的順序為:
w=0 1 2 3 0 1 2 3 0 1 2 3 4 5 6 7
星號(*)表示產生了page fault,所以一共產生了10個page faults。
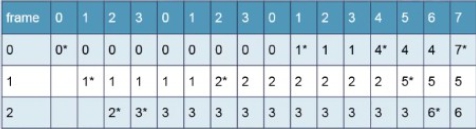
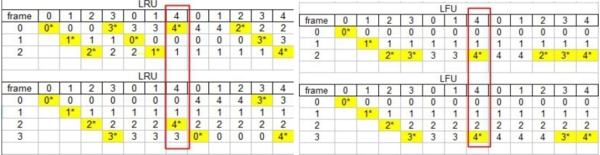
最久沒用的(LRU, least recently used)先替換的演算法選擇過去一段時間最久沒用到的分頁來替換。一共造成16次page faults。
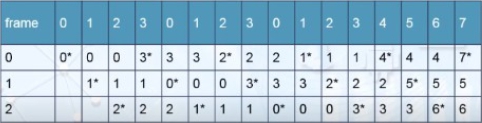
最不常用的(LFU, least frequently used)先替換的演算法選擇過去最不常用到的分頁來替換,可能有多個分頁都滿足條件,系統必須逕行選擇其一。一共造成12次page faults。
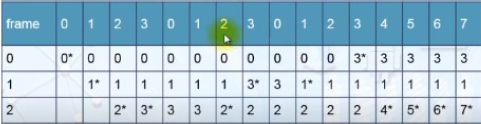
先進先出(FIFO, first-in, first-out)的置換演算法把存在於記憶體中最久的分頁先替換掉,FIFO判斷的標準是分頁在主記憶體存在的時間長短,所以很容易實作,但是跟多數程式執行時的實際行為有落差。一共造成16次page faults。
假設分頁引用的順序變成:
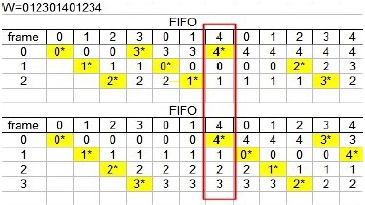
w = 0 1 2 3 0 1 4 0 1 2 3 4
假如分頁的配置採用FIFO,分配的page frames的數目為3,則依照表7-6的分析會產生9次的page faults,這時候我們可能會想到,若是增加分配的page frames的數目,可能page faults的數目會降低。假如現在分配的page frames的數目增加為4個,仍然採用FIFO的演算法,則依照表7-7的分析,一共會造成10個page faults,這是很奇怪的現象,也稱為Belady’s anomaly,為什麼分配的page frames增加了,page faults反而沒有減少?
對於某些分頁演算法在分配的page frames的數目增加時,原來可以載入的分頁的集合會是page frames數目增加以後載入的分頁的集合之子集合,也就是說,分配的page frames的數目增加,載入的分頁的數目除了原來載入的之外還會增加額外的分頁。這種特性稱為包含特性(inclusion property),這一類的演算法稱為堆疊演算法(stack algorithms),堆疊演算法不會有Belady’s anomaly的現象。
動態配置演算法會考量處理元執行過程中需求的改變,修正記憶體的配置情況。處理元引用記憶體位址的區域性關聯(locality)在此就可以派上用場,工作集演算法(working set algorithm)就是著名的動態配置演算法。
一個job的工作集(working set)是記憶體中job使用的pages的集合,當使用者開始執行程式以後,開始會有pages載入到記憶體中,經過一陣子以後,大多數的程式對於pages的存取都會進入穩定的狀態,很少有page fault發生,代表job會用到的pages都已經在主記憶體中,這些pages就形成了job的working set。
思考一下工作集中兩個重要的觀念:
1. 為什麼不乾脆把job的working set中所有的pages一次全部都載入到記憶體中呢? 首先,working set會隨locality而改變,所以除非是把所有用道pages都載入,否則無法全部一次都載入。
2. 分時系統中會有job swapping的現象,重新載入記憶體的job一開始都會產生很多page faults,影響系統的效能。
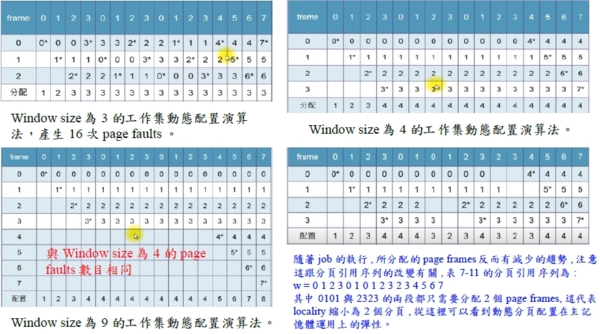
有很多paging system試著找出job的working set,然後在job開始執行前先把working set載入到記憶體中。不過在job開始執行之前要找出working set並不容易。Working set導入所謂的window size的觀念,代表進行判斷時需要考量的最近的分頁的數目,假設window size, ws=3,我們可以觀察以下的分頁引用順序:
w = ……0 1 2 1 0 1 2 ……
既然ws=3,表示working set是{0,1},因為從目前引用的page往前推(包括page本身)一共考量3個pages,所引用到的只有0與1兩個pages,所以job只需要2個page frames即可。除了window size以外,也可以用page fault的數目為指標,當這個數目高過某個門檻時,就把分配的page frames的數目提高,若是page fault低於某個數目,則可降低分配的page frames的數目。工作集演算法的效能和locality與window size都有關,通常若是window size太小的話,工作集演算法容易造成反覆置換(thrashing)。假如知道page faults的發生率,可以調整window size,例如page faults發生太快時,window size應該要大一點。
分段分頁的記憶體配置方法綜合了分段與分頁的記憶體配置方法,主要的目的是希望能獲得兩種方法的好處。在這個配置方法中,分段(segment)不再是單一的連續空間,而是細分成大小一致的pages。通常單一的分頁是要比分段來得小的。如此一來,可以避免分段法的一些缺失,例如external fragmentation。
分段分頁的記憶體配置方法需要下列4種表格:
1. 系統要保存一個記載處理中的jobs的Job Table。
2. SMT(segment map table)要列出每個分段的細節,每個job都有一個SMT。
3. 每個segment有一個PMT(page map table),用來記載每個page的細節。
4. 系統保存一個MMT(memory map table),用來監控page frames在記憶體中配置的狀況。

 留言列表
留言列表
